
namedtuple and dataclass | Python stdlib modules you should know
with examples, explanation, and best practices

Python’s stdlib is massive.
But there are a bunch of tools in there that can genuinely help you.
Every dependency you add is something that can break with updates, a security risk, and comes with its own philosophies and practices. stdlib is already installed, maintained by core Python team, and not disappearing soon (until the next major release, at least).
namedtuple and dataclass are two stdlib modules that you should absolutely learn about and abuse.
I’ve tried to explain using the official Python 3.14.2 stdlib docs but I understand that the docs can be intimidating at times. I’ve included Youtube videos - just make sure you grasp the core idea and try it on your own.
Let’s look at them; namedtuple and dataclasses
collections - namedtuple
Use: when you have functions that return multiple values, and the structure won’t change. I prefer dataclasses when I need mutability and more features (validation, methods, default values).
Instead of:
user = ("John", 28, "john@email.com")Do this:
from collections import namedtuple
User = namedtuple("User", ["name", "age", "email"])
user = User("John", 28, "john@email.com")
print(user)
# Output: User(name='John', age=28, email='john@email.com')
# unpacking
name, age, email = user
print(name)
# Output: John
Basically, namedtuple takes in a name (first argument) and attributes (rest of the arguments) and returns a class (child of the built-in class tuple). You then call a constructor to make objects. As a child of the tuple class, namedtuple is immutable and unpacks like a regular tuple.
And doesn’t consume more memory than regular tuples.

Here’s a video by Corey Schafer on namedtuple:
dataclass
dataclass is a decorator you add to classes (with lots of data). Compared to classes, they’re much neater. You can skip the boilerplate, and it’s more readable. Great!
With boilerplate: (regular class)
class User:
def __init__(self, name, age, email):
self.name = name
self.age = age
self.email = email
def __repr__(self):
return f"User(name={self.name}, age={self.age}, email={self.email})"
def __eq__(self, other):
return (self.name == other.name and
self.age == other.age and
self.email == other.email)
# Refactored with dataclass
from dataclasses import dataclass
@dataclass
class User:
name: str
age: int
email: strNotice how the dataclass decorator implements that __init__, __repr__ and __eq__ methods for free
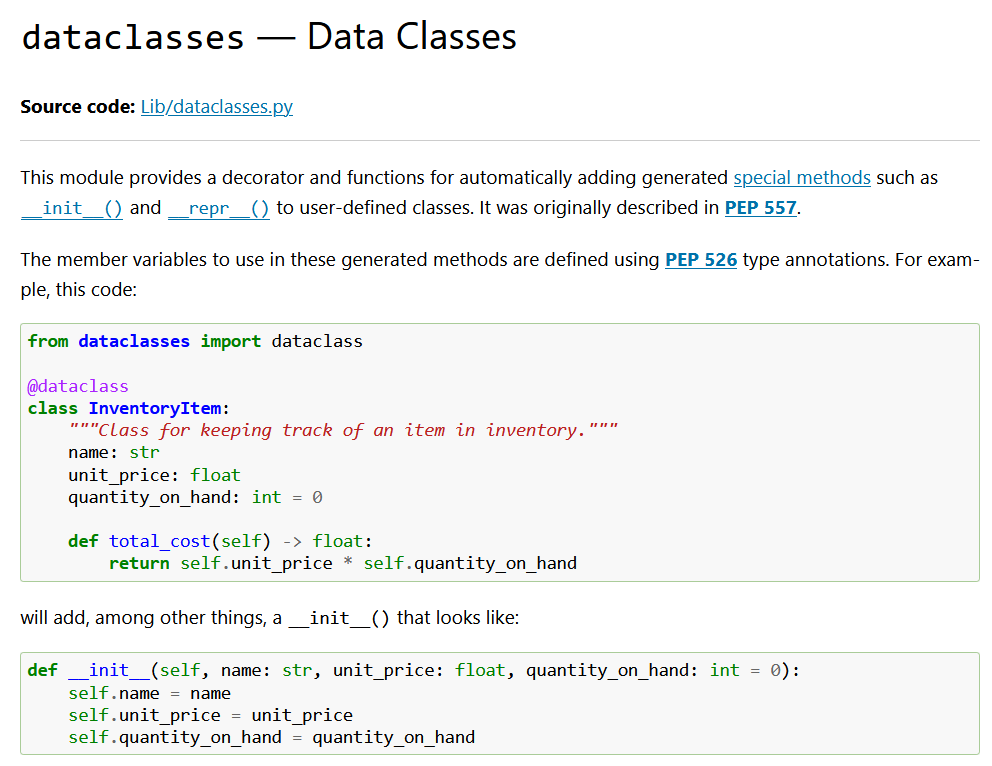
It supports defaults. You do need to use the field function if you’re using defaults for something other than primitives, but it’s still quite convenient.
from dataclasses import dataclass, field
@dataclass
class Config:
timeout: int = 30
retries: int = 3
debug: bool = False
headers: dict = field(default_factory=dict) # mutable default
config = Config() # uses defaults
config = Config(timeout=60, debug=True) # overriding someYou can even create immutable dataclasses like:
@dataclass(frozen=True)
class Point:
x: float
y: float
p = Point(1.0, 2.0)
p.x = 3.0 # Error: cannot assign to field ‘x’Here’s an awesome introduction to dataclasses by ArjanCodes:
Final Thoughts
namedtuple and dataclasses are very useful. These are just two of the powerful stdlib tools Python has to offer.
This post is the first in a series of stdlib deep-dives to come. The plan is to talk about something I find interesting.
Let me know if you want me to cover something in the next post!
What stdlib features do you use often that others don’t know about, and why?
Resources:
Python Module of the Week - Deep dives into stdlib modules
Official docs - stdlib reference